Example of a trade-off
I’m a programmer. I’m also a design prude. I’m also lazy. This all means that I spend a lot of my time chasing some different metrics in my code:
- How easy it is to read.
- How long it takes to run.
- How long it takes to write.
- …
These metrics are often at odds with one another. Just the other day I had to make a trade-off involving a function I’d written to evaluate a polynomial at a given point. Originally, it was written in a way that I felt was self-explanatory: it looped over the derivatives-at-zero of the polynomial, which were passed in as a list, and summed up the appropriate multiples of powers of x — a Taylor sum. Pseudo-code:
def apply_polynomial( deriv, x ):
sum = 0
for i from 0 to length( deriv ):
sum += deriv[i] * pow(x, i) / factorial(i)
return sumIt turned out that this function was a significant bottleneck in the execution time of my program: about 20% of it was spent inside this function. I was reasonably sure that the pow and factorial functions were the issue. I also knew that this function would only ever be called with cubics and lower-degree polynomials. So I re-wrote the code as follows:
def apply_cubic( deriv, x ):
sum = 0
len = length( deriv )
if len > 0:
sum += deriv[0]
if len > 1:
sum += deriv[1] * x
if len > 2:
square = x * x
sum += deriv[2] * square / 2
if len > 3:
cube = square * x
sum += deriv[3] * cube / 6
return sumSure enough, this improved the runtime significantly — by nearly the whole 20% that had been being spent inside this function. But notice that the code no longer contains the elements that define a Taylor sum: the loop is gone, and the factorials (0!, 1!, 2!, 3!) have been replaced with their values (1, 1, 2, 6). It also isn’t obvious why the length comparisons stop at 3. The code no longer explains itself, and must be commented to be understood. Readability has been sacrificed on the altar of efficiency.
Question
Why am I cursed so? Why can’t these metrics go hand-in-hand? And in general, why am I always doing this sort of thing? Sacrificing flavor for nutrition in the cafeteria, sacrificing walking-speed for politeness on a crowded sidewalk? Why are my goals so often set against one another?
Answer
Let’s take a second to think about what a trade-off is.
Suppose you’re faced with a problem to solve. You have two solutions in mind (Solution A & Solution B), and you have two metrics (Metric 1 & Metric 2) by which to judge a solution. A trade-off occurs when the solution that scores better along Metric 1 scores worse along Metric 2:
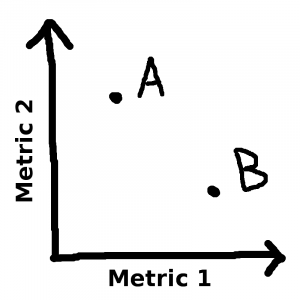
For example:
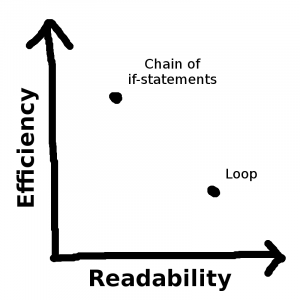
Of course, there need not be only two possible solutions. Maybe I’m willing to spend two hours working on improving this function, and depending on what I focus on, I could achieve any of the following balances:
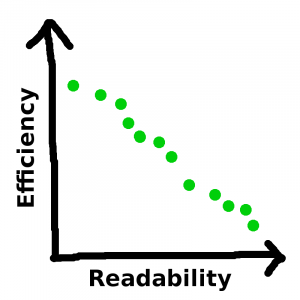
And — argh! The correlation is negative! Why!
Well, there’s a reason, and the reason is that this isn’t the full picture. This is:
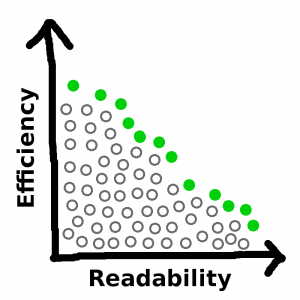
See, there are a whole bunch of ways to write the code that are neither as efficient nor as readable as one of the filled-in circles on the perimeter. But I would never choose any of those ways, for obvious reasons. And if a new solution occurs to me that beats out some of my old solutions along both metrics…
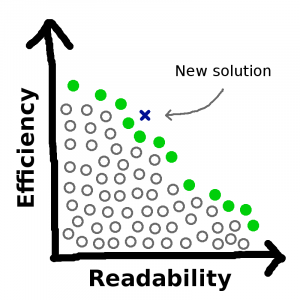
…then this new solution would replace all the solutions strictly worse than it, which in turn would become part of the mass that resides below the curve: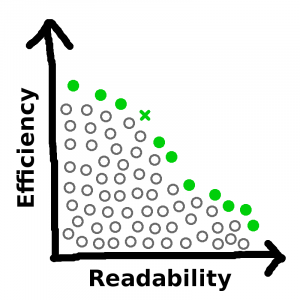
No matter how many new solutions are introduced into the mix, and no matter by how far they out-perform the old solutions, the outer frontier of non-dominated solutions must have negative slope everywhere. A step to the right along this line must be accompanied by a step downward, because if it isn’t, then the solution you just stepped off of is dominated by the one you just stepped onto, so the former wasn’t on the line.
It doesn’t take any math to generalize this result to situations where you have more than two metrics. Any solution that is dominated by another solution will be thrown out, so the options you end up considering form a set where no element dominates another, a.k.a. one where a gain along one metric entails a loss along at least one other, a.k.a. a trade-off. Throwing out obviously-poor solutions is easy (and is sometimes done subconsciously when you’re working in your domain of expertise, or done by other people before a decision gets to you), but weighing the remaining options usually takes some consideration. So, our subjective experience is that we spend most of our time and energy thinking about trade-offs. Q.E.D.
Note: On the LessWrong post, the user Dagon has written a comment explaining something that I meant to make more explicit in this post. Since they’ve expressed it better than I can, I’m just going to copy-paste their comment here:
One reason that most of your actual decisions involve tradeoffs is that easy no-tradeoff decisions get made quickly and don’t take up much of your time, so you don’t notice them. Many of the clear wins with no real downside are already baked into the context of the choices you’re making. For the vast majority of topics you’ll face, you’re late in the idea-evolution process, and the trivial wins are already in there.