In middle school, I had a really good teacher for social studies. (I don’t think I realized how good she was at her job until much later.) On one occasion, she wanted to demonstrate to us the difference between capitalist ideology and socialist ideology.
Her demonstration came in two parts: first, she handed out pieces of candy corn in random quantities to all the students, and told us we could play games of rock-paper-scissors with one another to increase our lot. Every time you won a game against someone, you got to take one of their pieces of candy. Games could only be initiated with consent from both parties, if I remember correctly. We played games for maybe five or ten minutes, and much candy corn traded hands. This was meant to represent capitalism.
Then, she collected all the candy and handed it out once again, this time giving exactly two pieces to each student. There was no trading phase in this round, so we just sat there for a few seconds considering the even piles of candy in front of us. This was meant to represent socialism.
Finally, with the second round of candies still on our desks, she asked us for our thoughts about which system was better. My own opinion, if I remember right, was that I favored the socialist way of handing out candy corn. (This is not an endorsement of establishing socialism as the arbiter of other resource conflicts.) I don’t remember most of what my classmates said, but the general consensus was that the capitalist system was better, because in that system, we had a hand in our own fate. If we weren’t happy with the amount of candy we got, we could, by golly, get up and do something about that.
(Interestingly, they also described capitalism as being “more fair”. I’m pretty sure I raised my hand at that point and said that, regardless of which option you think is better, the latter was clearly more fair. But at least one person persisted and said that fairness means having agency. At the time I thought that was dumb, but now I think it’s just invoking sense two of the word “fair”, where it means not that everybody gets the same treatment but rather that the outcome each person gets depends predictably on their actions. This is not to be confused with the equality/equity distinction, which looks at the first sense of the word “fair” and asks whether “same treatment” means “same opportunity” or “same outcome”. But this is a tangent to my main point in this post.)
(Also, I don’t think it mattered that rock-paper-scissors wasn’t a game of skill. Something something, it still imbued people with a sense of agency, something something.)
Anyway, the discussion wound down, and it was getting to be the end of class. The teacher had promised us that, yes, we would eventually have an opportunity to eat actual candy, and just before the bell rang she said we could eat the candy on our desks before we left. We did, and then we left.
Did you spot the problem?
I’ll give you a minute. Scroll down when you’re ready.
…
…
…
The problem is this: even though most people thought that the first system was better, nobody objected when the candy we actually got to eat was the candy given to us by the second system. I can’t say for sure, but I feel reasonably confident that if we, a group of middle schoolers, had been given random amounts of candy to actually eat, where the amount each student got was decided by the teacher’s whim, we would have lost our minds.
And, I think this would be true even if we’d had an opportunity to influence the amount we got. Somehow I think that if that had been what really decided the amount of candy we got to eat, rather than the amount of candy pieces that symbolized money but were ultimately just chips in a game… well, I think it would suddenly have seemed a lot more noticeable that some people didn’t have to influence the amount they got to end up with a lot, and others did. There seems to have been a dissonance between what my classmates endorsed and what they actually wanted — between what they objected to as an abstract idea and what they would have actually complained about if it had happened. Hence the title of the post.
(Somehow I also think the effect would have been especially strong in those who got the least candy to begin with. But that’s also a tangent to my main point, which is the dissonance thing.)
I don’t have anything especially insightful to say about this. I just thought it was kind of interesting.
Sylvanus, a professional programmer, has gotten into a car crash, with disastrous results: he’s paralyzed from the wrists down, and won’t be able to use a keyboard or mouse for six weeks while his hands heal. He has to take time off from his job, and worse, he has to take a break from his obsessive hobby of reading dozens of online news articles a day. He loves to stay up-to-date about current events, but no keyboard and no mouse means no surfing the internet, and the staff at the hospital are to busy to keep him in the loop.
Luckily, Sylvanus has a brilliant imagination, and since he’s on a break from life he has plenty of time to think. He lies in the hospital bed all day, relaxing his mind and sending probing thoughts out into the world, like a golfer putting a finger up in the air in order to check the direction of the wind. It isn’t long before he starts getting inklings about the outside world. They’re weak and vague at first, but they get stronger and clearer with each passing day of practice. He asks a nurse for a tape recorder, which he operates by pressing the buttons with his limp knuckles and which he uses to make spoken notes about the messages he receives.
After a few weeks of thinking and recording, he decides it’s time to review his notes. The process is challenging, since the messages are often incoherent or contradictory, but he feels up to the task, and before long he’s pretty sure he knows what he’s missed in world news since the accident.
The next day he gets a visit from his co-worker Daniella. She knows he’s a news junkie, and she offers to fill him in, but he decides to try to impress her. He explains his listening process, tells her what tweaks it needed to work more reliably, lets her listen to some of his notes, and then says:
“So, I think I already know what the news is. I’ll bet you five bucks I’ve got it right.”
“Huh,” she says. “Okay, deal. Start talking.”
He tells her what he came up with. Their country’s top official died of the flu three days after the accident, and was replaced by their second-in-command, as per the country’s founding document. But the second-in-command was incompetent and hugely unpopular, and was assassinated six days later. Everyone expected another high-ranking official to take their place, but a loophole was discovered stipulating that, in light of some specific details of the assassination, a general election should be held instead. All the major political parties raced to find suitable candidates, and…
“Okay, stop,” says Daniella. “Not sure where this is coming from, but it’s way off the mark. Nothing like that happened. You owe me five bucks.”
Sylvanus slumps in his bed, obviously disappointed.
“Why did you even offer that bet?” she asks. “Surely you know telepathy doesn’t work?”
But Sylvanus glares at her, and snaps “Well, I had nothing else to go on!”
This post is about abstract algebra. Specifically, I’m going to take a look at the reasoning behind associativity, the property of binary operations which requires that, for any triplet of values:
(A∘B)∘C = A∘(B∘C)
where ∘ is the operation in question. For example, addition is associative because for any three numbers, A, B, and C, the values (A+B)+C and A+(B+C) are equal.
This property is required by groups, fields, lattices, and many other algebraic structures. I’ll start off with a review of groups, which are probably the most widely studied of the lot, and then I’ll dive right into my analysis. The review only serves as background context, so you can skip it if you want to get straight to the point (or if you’re already familiar with groups).
Groups
A group is a set G paired with a binary operation satisfying four properties. For now, I will write the operation as multiplication, i.e. if a and b are two elements of a group then I will use ab to refer to the result of applying the operation to the pair (a, b). The required properties are:
Closure: If a and b are members of G, then ab is a member of G.
Existence of an identity: G contains an element e such that combining e with any other element leaves it the same (i.e. ea = ae = a for all a in G). You can think of this as the “do nothing” element.
Existence of inverses: For any element a in G, there is an element you can combine it with to produce the identity (i.e. ab = ba = e for some b in G). You can think of this as saying that, whatever you can do with an element of G, you can also undo with some other element (or possibly the same one — sometimes an element is its own inverse).
Associativity: For any three elements a, b, and c, the equation (ab)c = a(bc) must hold.
For example, G could be the set of all integers (positive and negative) and the operation could be normal addition. Let’s check that all the axioms are satisfied:
Closure: The sum of two integers is always another integer. ✓
Existence of an identity: Zero is an identity, since adding zero to any integer leaves it the same. ✓
Existence of inverses: For any integer X, the number “negative X” is also an integer, and their sum is (X) + (-X) = 0, which is the identity element. ✓
Associativity: This one isn’t so easy to prove. Most of us learned that addition is associative in elementary school and never questioned it. It isn’t even obvious what you’re allowed to assume along the way to proving this fact — if the associative property of addition can’t be taken for granted, what can? See the Peano Axioms for more about this, and see this Wikipedia page for the proof. For our purposes, we can just say “✓” and be done with it.
There are countless other examples, too:
G is the set of positive real numbers and the operation is normal multiplication.
G is the set of 2×2 invertible matrices and the operation is matrix multiplication.
G is the set {0, 1, 2, 3, 4, 5, 6, 7} and the operation is addition modulo 8. Yes, groups can be finite in size.
G is the set {A, B, C, D, E, F} and the operation is defined by this look-up table:
Yes, look-up tables are allowed. Nowhere in the group axioms does it state that the operation has to be something familiar. You can verify that the axioms still hold: the identity is A, inverses can be found manually, and associativity can be proven laboriously for each triplet of letters. For example (DC)F = EF = C, while D(CF) = DE = C.
Note that this operation isn’t commutative; some pairs of elements have a different product depending on the order you multiply them in. CE = D but EC = F. This operation manages to be associative despite not being commutative. Yes, that’s allowed. Anything not directly or indirectly ruled out by the group axioms is allowed.
Groups where the order of multiplication makes a difference are called non-abelian. For an infinite number of examples of finite-sized, non-abelian groups, see the dihedral groups.
Why associative operations?
Anyway, what I’m here to talk about today is that the associative property never used to make sense to me — who cares about associative operations? Why that restriction and not something else?
It turns out that the key to understanding it is a very simple dictum: parentheses don’t matter. Since A(BC) and (AB)C are guaranteed to be equal anyway, you might as well toss out the parentheses and just write ABC. It doesn’t matter which of the two “explicit” versions you’re referring to, because they both have the same value. And, very importantly, the same goes for longer sequences. A((BC)(D(EF))) is equal to ((AB)(CD))(EF) by the following chain of manipulations, applying the associative property over and over again:
A ((BC) (D(EF)))
(A (BC)) (D (EF))
((AB) C) (D (EF))
(((AB)C) D) (EF)
((AB) (CD)) (EF)
And in fact, any two parenthesis-filled versions of ABCDEF can be shown to be equal by similar chains of manipulations. Citation needed. Don’t worry, I’ll prove this in a minute. Right now, just think about the implication: since parentheses never matter, you can think about groups not as having binary operations — maps from pairs of elements to single elements — with the associative property, but rather as having sequential operations — maps from sequences of elements to single elements — perhaps with some additional properties.
I say “perhaps with some additional properties” because we haven’t yet determined whether every sequential operation comes from an associative binary operation, only that every associative binary operation can be transmogrified into a sequential one. There might yet be some “orphan” sequential operations that you’d never create, no matter how many associative binary operations you transmogrified. We will investigate this later on in the post.
Proof of my claim
Lemma: The value that an associative binary operation assigns to a parenthesized sequence of elements doesn’t depend on the positions of the parentheses.
Proof: Let S be such a sequence. For example, S could be ((A(BC)) (DE)) (F(GH)). We’re going to show that any such sequence such sequence can be re-arranged into a fully right-associative sequence, in this case A(B(C(D(E(F(GH)))))), without changing its value. It will follow that all starting sequences have the same value.
The first step is to use the associative property to re-arrange S so that the left side of the top-most application of the operation is a single element. If this is already so, we can move on. Otherwise, we can make it so by the following process. Since the left side is not a single element, it must be a product of two elements. In this case, the left side is the product of (A(BC)) and (DE). In other words, the overall structure of S is (x y) z.
Now, by the associative property, we can re-arrange this into x (y z) without changing its value:
Now our sequence is (A(BC)) ((DE) (F(GH))). Its left side is smaller than it was before: three elements instead of five elements. But it still has the form (x y) z, so we can apply the same transformation again:
This transformation can be repeated as many times as necessary, until you get a sequence whose left side is a single element, a sequence that begins A (…). In this case, it took two applications. Once you’ve pulled the first element out to the front, you recurse. Apply the same process to the right side of the sequence, until its left side is a single element, so that the sequence begins with A (B (…)). Then recurse again, pulling out yet another element to achieve A (B (C (…))). Recurse over and over until you achieve the fully right-associative sequence. Since we only transformed the sequence by applying the associative property, its value has not changed. This completes the proof. □
The tower-of-powers counterexample
I said earlier in this post that we don’t yet know whether every sequential operation has an underlying associative binary operation. Well, I’ll tell you one that doesn’t: the operation that assigns to a sequence (A, B, C, …) of integers the value of:
ABC…
…a tower-of-powers with one entry for each element.
The proof is easy, but let me start with some notation. I will denote applications of sequential operations with [square brackets]. So, for the sequential operation defined above, I could write:
[3 3] = 33 = 27
[2 2 2] = 222 = 16
[1 6 7 8] = 1678 = 1
[5 4 3] = 543 ≈ 5.4 * 1044
Also, since there are now two different operations under discussion, I will use ∘ to denote a binary operation — i.e. I will now write a∘b instead of just ab.
Now, the proof. Suppose the sequential operation [] defined above really does derive from some binary operation ∘. In other words, suppose that [2 3 4 5] is really just a shorthand for “apply ∘ to the operands 2, 3, 4, and 5, with parentheses anywhere you want”. We can figure out what value that operation must spit out for any pair of just two inputs a and b, since by definition [a b] must equal a∘b. So my proof is simply to note that:
Since these two values aren’t equal, ∘ isn’t associative. QED!
Now, here’s a (tangential) harder question. Suppose the operation [] is defined as above, but only for sequences of three or more elements. In other words, suppose that the 2-ary version of the operation is surgically removed, so that it’s no longer so easy to determine the exact values of a hypothetical underlying binary operation. Could the 2-ary version of the operation then be replaced in some fashion such that one would exist? I will include the answer to this question in a spoiler box at the end of this post. The material in the next section will render the puzzle easier, so consider pausing here and coming back when you’ve solved it.
And vice versa
So parentheses don’t matter for an associative binary operation. Is it obvious to you that parentheses also don’t matter for a sequential operation that derives from an associative binary operation? If so, then you’re either slightly quicker than me or slightly overconfident. But in any case, it’s true.
Lemma: If ∘ is an associative binary operation and [] is the corresponding sequential operation, then the value that [] assigns to a bracketed sequence of elements is independent of the positions of any extra internal brackets.
Proof: Let S be such a sequence. For example, S could be the sequence [A B C [D E] F [G H [I J] K L] ]. (Note that “bracketed sequence of elements” means something slightly different than “parenthesized sequence of elements”, since the fact that we’re working with a sequential operation instead of a binary operation means that more than two elements can appear between a given pair of brackets.) Now, replace each application of [] with repeated applications of ∘, parenthesized however you like. For our sequence, this might yield:
But this too is a parenthesization of the given sequence of elements, and as such it is equal in value to any other parenthesization, and to the plain application of [], in our case [A B C D E F G H I J K L]. Hence the value that [] assigned to S did not depend on the positions of the extra brackets. □
—
But now look:
Lemma: If [] is a sequential operation whose value doesn’t depend on the positions of the brackets, then it corresponds to an underlying associative binary operation ∘.
Proof: Take the binary operation to be the 2-ary version of the sequential operation. In other words, define A∘B = [A B]. Then:
(A∘B)∘C = [[A B] C] = [A [B C]] = A∘(B∘C)
and we see that ∘ is associative. And it is easy to see that [] is the sequential operation that corresponds to ∘, because any parenthesized sequence of applications of ∘ can be transformed into a corresponding bracketed sequence of applications of []. Then the extra brackets can simply be removed, since the value of [] doesn’t depend on them. For example:
(A∘B)∘(C∘(D∘E)) = [[A B] [C [D E]]] = [A B C D E]
So we see that repeated applications of ∘ always yield the same value as a single application of the sequential operation. ◻
—
So there it is — every binary associative operation corresponds to a sequential operation whose value doesn’t depend on internal brackets, and vice versa. The two types of operation are the same, and can be used interchangeably.
The ghosts of departed sequences
How can we leverage this discovery to improve our intuitions about groups and other associative algebraic structures?
Take a moment to consider the Rubik’s Cube group, which is a group of all possible permutations of a Rubik’s cube.. For example, the element R is the permutation you get if you turn the right side clockwise one quarter-turn, and the element LLL is the permutation you get after turning the left side clockwise three quarter-turns (or counterclockwise one quarter-turn). What about LLLL? That’s the same as the solved permutation, since turning the left side four times in a row returns you to the starting state. The other four sides are called U for “up”, D for “down”, F for “front”, and B for “back”.
It’s easy to see what the sequential operation of the Rubik’s Cube group is — given a sequence of permutations, you simply apply one permutation after the other. [LLBRF] = LLBRF. It’s also easy to see that extra brackets don’t matter. Consider these two applications of the operation:
[L B U D]
[L [B U] D]
The two sequences are the same, except that the second one has an extra set of brackets. Now, what would it mean for them to have different values? “Turning the left, then the back, then the top, then the bottom is different from turning the left, then the back and top in succession, then the bottom.” If that sounds strange to you, then you have all the intuitions you need already in place. “Apply each of these individual operations in sequence” is an inherently structureless notion. There’s no possible concept that would be analogous to adding parentheses to the written-out sequence of moves.
Or consider the group of 2×2 linear transforms, like “compress by a factor of 2 in the x direction” or “rotate 45 degrees”. Suppose you’ve got four transforms that you’d like to compose with one another — A, B, C, and D. Would it make any sense for [A B C D] to be different from [A B [C D]]? “First apply A, then apply B, then apply C and D really fast without stopping for breath. Make sure those last two really count as being just one big move, since they’re supposed to be grouped together.”
Or for that matter, take the group of integers under addition. “Start with four, then add the sum of three and six, then add nine”. Think back to first grade, when adding two numbers together meant combining two piles of mangos and counting how many you ended up with. What am I going to do to denote that the three mangos are being added to the six mangos before I add them all to the pile? Put them in a ziploc bag together?
In fact, forget the other properties of groups. There’s another algebraic structure called a semigroup that only requires closure and associativity, and not identity or inverses. The set of all real functions is a semigroup under the operation of function composition. For example, consider the elements F(x) = x2, G(x) = sin(x), and H(x) = 3x. You can see the operation in action:
(F∘G)(x) = (sin(x))2
(H∘F∘H)(x) = 27x2
(G∘G∘H∘H)(x) = sin(sin(9x))
Or, if you prefer:
[F G](x) = (sin(x))2
[H F H](x) = 27x2
[G G H H](x) = sin(sin(9x))
And again it’s the same question. Could [G [G H] H] possibly differ from [G G H H]? Not really. “First put x through H, then quickly put it through H and then G, then put it through G.” There just isn’t room for there to be a difference.
But above all, consider the tower-of-powers sequential operation. It does not correspond to any associative binary operation at all, because in the context of exponentiation, the elements of the set of positive integers cannot be thought of as a set of actions that you take one after another. At least, not if you want to add new elements on the right.
What do I mean? Well, suppose you’ve got some sequence that ends in 3, like this: [… 3]. Since brackets aren’t supposed to matter, you decide to add an extra pair of brackets to make [[…] 3], so that you can evaluate all that stuff on the left first. Say the stuff on the left evaluates to 16. What should the final value be?
Well, if the subsequence you just collapsed was [2 2 2] then the original sequence was [2 2 2 3] and you should get an answer of 2256. But if the subsequence was [4 2] then your answer should be [4 2 3] = 216, and if it was just a plain [16] then you should get [16 3] = 212.
If the tower-of-powers operation were associative — that is, if extra parentheses didn’t affect the answer you get — then any time you apply 3 to something, that thing should behave just like any of its expansions would.
Just like how BU from the Rubik’s Cube group behaves exactly like the sequence [B U] does. Or how the linear transform [C D] behaves just like the linear transform D followed by the linear transform C. Or how adding nine mangos to a pile is the same as adding six and then adding three more. Or how composing sin(3x) onto another function is the same as composing 3x and then composing sin(x).
In each of these cases, the individual element resulting from a collapse of a sequence [S1 S2 S3 …] has managed to retain all of the qualities of the original sequence that were relevant for performing further applications of the operation. It’s as though the individual element were possessed by the ghost of the sequence it came from.
But this isn’t the case for the tower-of-powers operation. When [2 2 2] is collapsed into 16, you lose the information about where in the stack any further elements are supposed to go. Before collapse, you know it’s supposed to go at the top of a stack of three 2’s. But after the collapse, that 16 could just as well have come from [4 2] or [16 1 1] or whatever, and those guys have different ideas of where further elements are supposed to go. This kind of thing doesn’t happen in the other cases. That’s what it really means for an operation to be associative.
Now, use this newfound understanding to explain to me in the comments why it’s obvious that gcd, the greatest-common-divisor function, is associative.
Post-script 1: solution to the puzzle
This is the solution to the puzzle presented in the section about the tower-of-powers sequential operation. I won’t repeat the puzzle here. If you want to see the answer, click the button below.
Answer: No, it can’t.
Proof: By the lemma above, if [] had an underlying associative binary operation, then the value it assigned to sequences of elements wouldn’t change if you add extra brackets. You have to be a bit careful here, since its value is only actually defined for sequences of three or more elements. However, there is an example of a nine-element sequence whose value differs depending on the presence or absence of extra brackets:
[2 1 1 2 1 1 2 1 1] = 2
[ [2 1 1] [2 1 1] [2 1 1] ] = [2 2 2] = 16
Which means that [] can’t possibly have an underlying associative binary operation. □
…And now I suppose you want a solution that doesn’t invoke a lemma that you didn’t have available when the puzzle was posed to you. Okay, here’s one. Suppose ∘ is an associative binary operation corresponding to the given []. While it’s true that we can’t figure out what value ∘ spits out for individual pairs of numbers, we can figure out what value it spits out for triplets and longer lists of numbers, since those arities of [] were left intact. So now my proof is to note that the following sequence:
2∘1∘1∘2∘1∘1∘2∘1∘1
can either be interpreted as a triplet of triplets, in which case it must evaluate to 16, or it can be interpreted as one long nine-tuple of numbers, in which case it must evaluate to 2, which is a contradiction. This is basically the same proof as above, except it points out the problem more directly.
Post-script 2: infinite sequences
“Aha!” says the careful reader who isn’t very familiar with abstract algebra, after reading the first proof in this post. “But what about infinite sequences of elements? Your proof implicitly uses induction to show that parenthesized sequences of arbitrary length can be re-arranged into fully right-associative sequences, but induction only works for the finite case.”
My answer: the the normal definition of associative operations does not guarantee the existence of infinite products. Consider the group where G is the set {1, 3, 5, 7} and the operation is multiplication modulo 8, and try to find the value of the expression 3∘3∘3∘3∘3∘… with a countably infinite number of threes. You could try taking a limit of the product of N threes as N goes to infinity, but…
3∘3 = 9 mod 8 = 1
3∘3∘3 = 27 mod 8 = 3
3∘3∘3∘3 = 81 mod 8 = 1
3∘3∘3∘3∘3 = 243 mod 8 = 3
3∘3∘3∘3∘3∘3 = 729 mod 8 = 1
…
…you won’t find one. Because who said there would be one, anyway? One’s mind might turn to infinite sequences once operations are framed as acting on sequences of elements, but the original definition only calls for a binary version, and if you can’t find any sensible way to define the value of an infinite product like this one, that’s just too bad.
Post-script 3: the look-up table group
But what about the six-element group with a lookup table for an operation that I defined at the start of this post? Do the intuitions built herein not apply to that group?
Sure they do. You just need the right interpretation of what the elements of that group actually are. Consider this equilateral triangle:
Each element of the group corresponds to an action you can take on the triangle that doesn’t change its appearance. There are six such actions:
Do nothing.
Rotate left 120 degrees.
Rotate left 240 degrees.
Flip over the vertical axis.
Flip over the vertical axis, then rotate left 120 degrees.
Flip over the vertical axis, then rotate left 240 degrees.
Applying any number of these actions in sequence is always equivalent to performing just a single action. For example, 2∘4 = 6 and 3∘3∘3 = 1. If you’ve been following along, it should be obvious that the operation is associative. The identity element is action 1 and inverses are easy to find experimentally. Try cutting out a paper triangle and marking the front and back with distinct, asymmetrical symbols, such as the letters F and B. Play around with it to get a feel for how the actions interrelate. I will leave it as an exercise to you to discover which elements of the group correspond to which actions. Hint: there may be more than one solution.
I’ve just come across this web page, which has some puzzles regarding infinite graphs. I’ve solved the first ten, and they’re nice. Some examples include:
Describe all graphs with a countably infinite number of nodes such that every vertex has degree two.
If possible, describe a graph with a unique vertex of every degree.
The first one is easier, IMO. If anyone’s curious, I can write up my solutions to all ten problems in another post.
Anyway, I found this page because I was looking for information about infinite graphs in general, which I’m interested in because of a new graph-representation schema I’ve come up with. Everybody knows the two standard representations:
Keep a list of nodes and a list of edges.
Keep track of a square matrix whose entry at (r, c) is 1 if node r is connected to node c and 0 if it isn’t.
But these only work for finite graphs, and I started wondering if there was a representation that would work for infinite graphs too.
The first idea I came up with was to represent a graph as an algorithm whose input is the name of a node and whose output is a list of nodes that are adjacent to it. Actually, this representation has an issue where if a node N has an infinite number of neighbors, then you can’t stuff them all into a list on a computer with finite memory. But you can get around this by instead returning an iterator — an object that you can keep calling .next() on and it keeps computing and returning the next element of an infinite sequence. Folks on the functional-programming side of the aisle can think of the neighbor-finding algorithm as returning another algorithm, whose input is an integer k and whose output is the kth neighbor of the original node N.
The other idea I had is to represent a graph as an algorithm whose input is the names of two nodes, and whose output is 1 if the nodes are connected and 0 if they aren’t.
Of course, both of these representations only work for graphs with a countable number of nodes, since the finite-sized inputs to a computer algorithm can’t encode a choice among an uncountable number of options. (Obviously in practice you will only ever inspect a finite portion of any graph. But you can still represent the whole thing as long as it’s countable, and as long as you consider “this algorithm would compute the right answer for any of the infinitely many inputs, if only I had time to try them all” as an acceptable form of representation.)
But more interestingly, I’m wondering what the limitations of this schema are. There are certainly some countable graphs you still can’t represent, such as the graph whose nodes are integers and whose edges only connect consecutive Busy Beaver numbers, which famously can’t be computed by any algorithm. But before I can investigate what sorts of infinite graphs can’t be represented by this algorithm, I need to investigate what sorts of infinite graphs exist — hence, my interest in infinite graphs.
PS: I realized while editing this post that my suggested graph actually can be represented by my schema. Simply connect all positive even numbers in an infinite chain and leave every other node isolated (eg, no neighbors). This has a different labeling of nodes than the Busy-Beaver graph, but the two are isomorphic to each other. Since I’m currently only interested in representing unlabeled graphs, this means the two are identical in my eyes. But here’s one that doesn’t suffer from the issue: let K(n) be the fully-connected graph with n vertices and let B(n) be the nth busy-beaver number. Then the union over all integers i of K(B(i)) is an graph that can’t be represented by any algorithm.
This story was originally for my alt, Van’s Blog. NB: That blog has a gimmick, which is that I don’t post anything with E’s in it. As such, this story’s wording is a bit unusual. Original post.)
Without ado:
On a cool autumn day, two girls found a dark hollow. At 14 and 16, Otu and Lai had no grasp of what risks its winding corridors could hold. Lai, always an analyst, was curious what lay at its bottom, if it had a bottom at all. Otu, young and timid, saw no option but to tag along.
It wasn’t long until that hollow’s mouth was a long-ago ghost of a thought. Lai’s hand ran along dank rock walls just to find a way to walk; sunlight had all but quit our protagonists.”I know this wall!” Lai would say now and again. “Now I can find us a way out!”
On no occasion did this pan out, and following six dud calls, Lai didn’t try again.
“Damn,” said Lai at last. “Okay, I couldn’t hold a full map of this hollow in my mind. But you know what? Turning right at all junctions should work to bring us back out. That’s a fact I know from math class, so it has to work.”
But that was a no-go too; it wasn’t always turning right that would bring you out; it was alwaysfollowing a wall that would do it. Lai’s slip cost an hour, at which point both girls had to stop walking and sit down for a bit. Gloom sprung up, and spans of quick sobs took turns with spans of calm.
Finally Otu lay down, admitting that touching a bit of dirt was worth not having an aching butt from sitting for so long. Might so much as a nap stand as too high a wish?
It did, for Otu’s torso hit not ground but a plastic chassis.
“Ouch! What was that?”
Lai sat up. “What’s what?”
Otu’s hand found it, took it, hit it, hit it again, and ran along its plastic skin, trying to find out what it was. It was long-ish, a tubular form, with a sort of protrusion on its top. It was mostly rough and hard, though its protrusion’s front was smooth and glassy. It also had a small switch on it. Flipping that switch did nothing at first, but…
O brilliant light! Abruptly a hollow priorly dark and boding was brightly lit and allowing, possibly, of a happy conclusion.
Otu’s jaw hung, and said nothing.
“Fascinating!” said Lai. “Can I hold it?”
Now it was Lai’s hand that took it, hit it, ran along its plastic skin. It was an amazing apparatus, and Lai was profoundly curious how it did what it did. So captivating, just to look at it…
Shortly, Otu said “Um, don’t you want to start trying to find our way out? I think with this much light it won’t—”
“Hang on, hang on,” said Lai. “I want to know how this thing works. Light must form in this part, right? Or no, wait, it could build up in this long body and spill out on command. This switch could control a trap door. Oh, or mayhap God monitors it and calls down light if—”
“Lai! I know this stuff is fun for you, but shouldn’t you and I focus on finding a way out first?”
Lai wasn’t paying any mind. “—a mirror. That way any light it spawns would, uh… oh! Or it could just trick you into thinking it’s making light, but it’s actually an illusion! If that’s it, it’s still dark, and using this thing to try to find a way out will bring us away from our goal. Or—”
Otu was almost crying now. “What? You know it’s light, just look! How can you find that stupid contraption so alluring right now?”
This didn’t stop Lai’s mumbling and puzzling. No, nothing could stop it at this point. Lai’s curiosity had no bounds and no limits: it could sustain a distraction for infinity, blind to crucial situational factors, blind to rising panic, blind to logic.
And so, our two girls stood in a dark hollow’s gut, having a tool that could bring faith of finding a way back out, but failing to apply it to that task. For all that tool could do, for all its magic — that was void if its cryptic quality was too much of a distraction for its claimant to actually put it to work.
I’m afraid my story cuts off at this point — I don’t know if Otu and Lai got out of that hollow. I want to think that Otu finally got to Lai, that what was actually important finally won out against what was shiny and fun to think about. But I don’t know.
Stay vigilant, folks. Lai’s flub looks obvious from this standpoint, but foolish distraction is an insidious bastard — anybody can fall victim to it.
Note: This post was back-ported from LessWrong. You can find the original here.
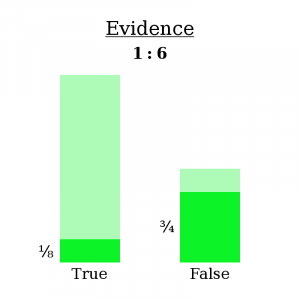
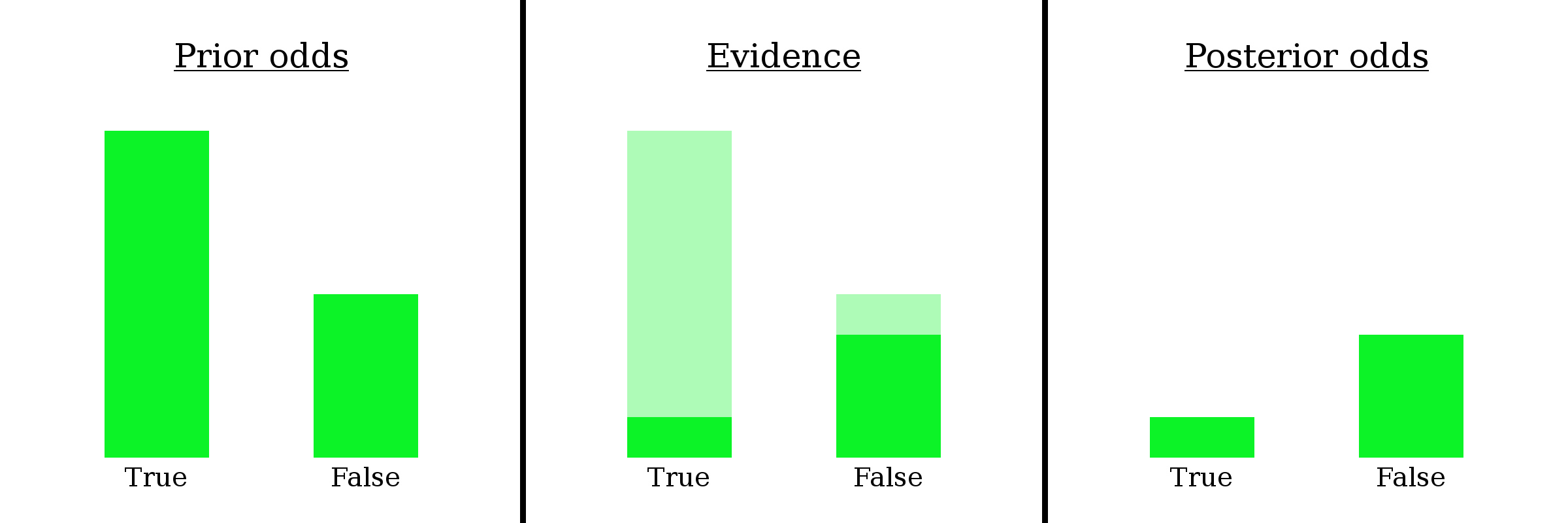
Let’s say you have a belief — I’ll call it “B” for “belief” — that you would assign 2:1 odds to. In other words, you consider it twice as likely that B is true than that B is false. If you were to sort all possible worlds into piles based on whether B is true, there would be twice as many where it’s true than not.
Then you make an observation O, which you estimate to have had different probabilities depending on whether B is true. In fact:
If B is true, then O had a 1/8 chance of occurring.
If B is false, then O had a 3/4 chance of occurring.
In other words:
O occurs in 1/8 of the worlds where B is true.
O occurs in 3/4 of the worlds where B is false.
We know you’re in a world where O occurred — you just saw it happen! So let’s go ahead and fade out all the worlds where O didn’t occur, since we know you’re not in one of them. This will slash the “B is true” pile of worlds down to 1/8 of its original size and the “B is false” pile of worlds down to 3/4 of its original size.
Why did I write Evidence: 1:6 at the top? Let’s ignore that for a second. For now, it’s safe to throw away the faded-out worlds, because, again, we now know they aren’t true.
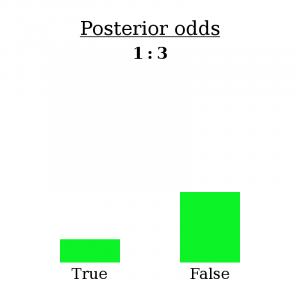
I’m going to make a bold claim: having made observation O, you have no choice but to re-asses your belief B as having 1:3odds (three times as likely to be false than true).
How can I say such a thing? Well, initially you assigned it 2:1 odds, meaning that you thought there were twice as many possible worlds where it was true than where it was false. Having made observation O, you must eliminate all the worlds where O doesn’t happen. As for the other worlds, if you considered them possible before, and O doesn’t contradict them, then you should still consider them possible now. So there is no wiggle room: an observation tells you exactly which worlds to keep and which to throw away, and therefore determines how the ratio of worlds changes — or, how the odds change.
What about “Evidence: 1:6”?
Well, first notice that it doesn’t really matter how many worlds you’re considering total — what matters is the ratio of worlds in one pile to the other. We can write 2:1 odds as the fraction 2/1. The numerator represents the “B is true” worlds and the denominator represents the “B is false” worlds. Then, when you see the evidence, the numerator gets cut down to 1/8 of its initial size, and the denominator gets cut down to 3/4 of its initial size.
We can write this as an equation:
(2 ∗ 1/8) / (1 * 3/4) = 1/3
Now notice something else: it also doesn’t matter what the actual likelihood of observation O is in each type of world. All that matters is the ratio of likelihoods of O between one type of world and the other. O could just as well have been exactly 10 times less likely in both scenarios…
(2 ∗ 1/80) / (1 * 3/40) = 1/3
…and our final odds come out the same.
That’s why we write the evidence as 1:6 — because only the ratio matters.
This — the fact that each new observation uniquely determines how your beliefs should change, and the fact that this unique change is to multiply by the ratio of likelihoods of the observation — is Bayes’ Theorem. If it all seems obvious, good: clear thinking renders important theorems obvious.
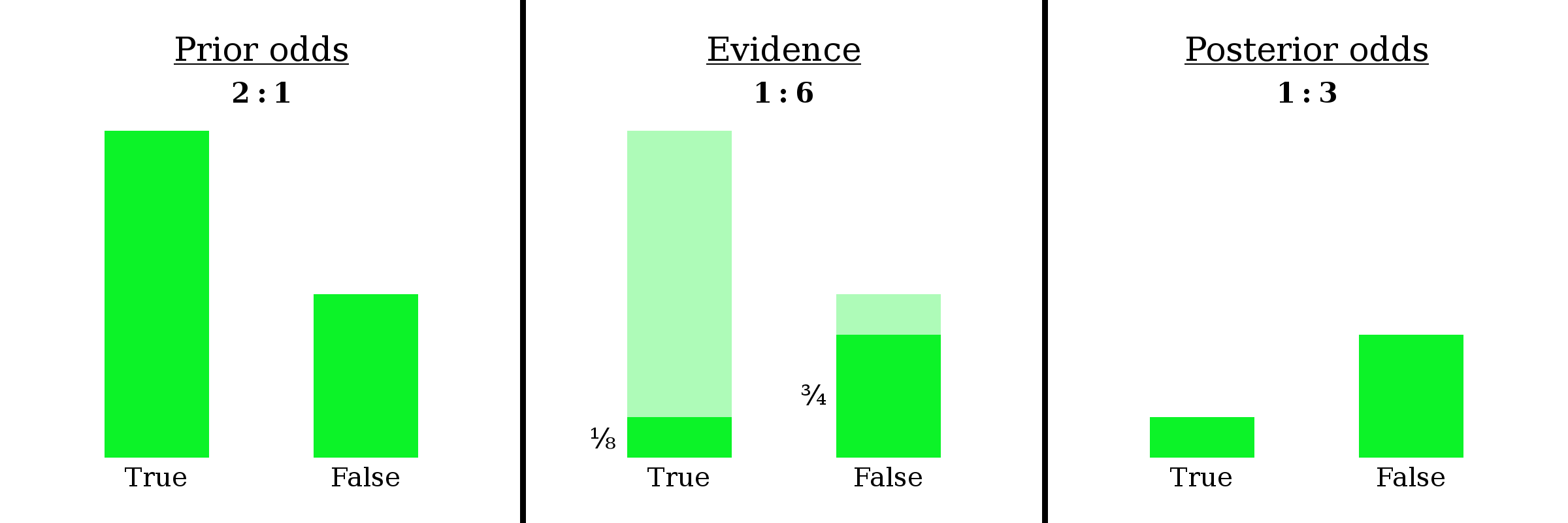
For your viewing pleasure, here’s a combined picture of the three important diagrams.
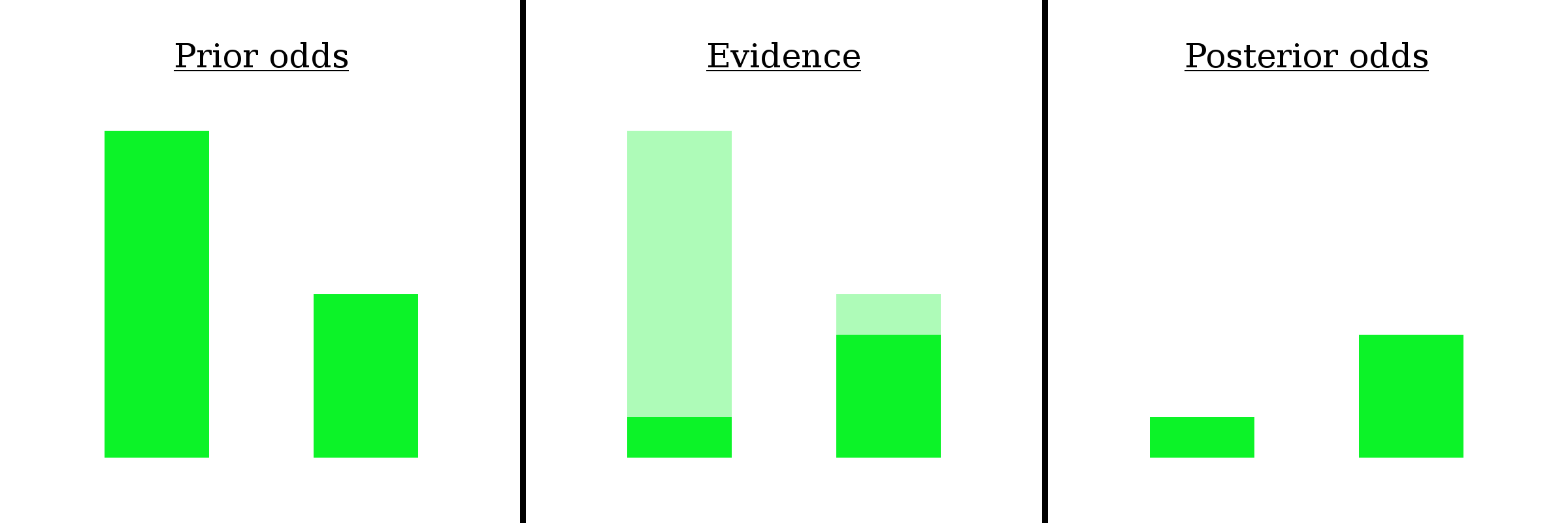
And here’s a version without the numbers and here’s a version where the bars aren’t even labeled.
An example
On the LessWrong version of this post, user adamzerner suggested I add a concrete example. I’m happy to oblige!
Example: Mahendra has been found dead in his home, killed by a gunshot wound. Police want to know: was this a suicide or a homicide?
The first step is to establish your prior; in other words, what odds [homicide : suicide] do you assign this case right off the bat?
Well, according to Vox, about 40% of gun-related deaths are homicides and 60% are suicides. The number has varied a bit throughout the years, but let’s go ahead and use this figure. A 40%/60% chance equates to 2:3 odds — for every two homicides by gun, there are three suicides by gun. This is called the base rate, and it will serve as our prior odds.
It’s worth repeating that what you see above represents the fact that, if you sorted all possible worlds into piles based on Mahendra’s cause of death, you would see three in the “suicide” pile for every two in the “homicide” pile. (It’s okay if there are other modes of death under consideration too, such as “accident” — the same logic would still apply! For simplicity, I’ll just use these two.)
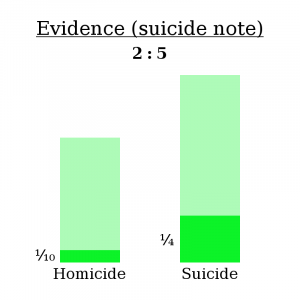
After a bit of investigation, a some evidence has turned up — a suicide note! Open and shut case, right?
Think again. Some murderers are smart — they’ll plant a fake suicide node at the scene of the crime to cover their tracks. I couldn’t find an exact statistic, but let’s say about 1/10 murderers think to do this.
Also, not every suicide has a note. In fact, Wikipedia reports that only about 1/4 of suicides include a note.
In other words:
If Mahendra’s death was a homicide, there was a 1/10 chance of finding a note.
If Mahendra’s death was a suicide, there was a 1/4 chance of finding a note.
So now, let’s follow the same process as before.
Here’s the math bit:
(2 ∗ 1/10) / (3 * 1/4) = 4/15
So, as expected, finding a suicide note makes the “homicide” explanation less likely — 4:15 odds compared to 2:3 odds, or about a 79% chance of suicide compared to a 60% chance initially.
However, be aware that this isn’t because most suicides include a note. In fact, most suicides don’t include a note. The reason it makes suicide more likely is that even fewer homicides include a note. It’s not true that “most suicides have a note”, but it is true that “suicides are more likely to produce a note than homicides are”. That’s what makes for proper bayesian evidence.
Note: This post was back-ported from LessWrong. You can find the original here.
Example of a trade-off
I’m a programmer. I’m also a design prude. I’m also lazy. This all means that I spend a lot of my time chasing some different metrics in my code:
How easy it is to read.
How long it takes to run.
How long it takes to write.
…
These metrics are often at odds with one another. Just the other day I had to make a trade-off involving a function I’d written to evaluate a polynomial at a given point. Originally, it was written in a way that I felt was self-explanatory: it looped over the derivatives-at-zero of the polynomial, which were passed in as a list, and summed up the appropriate multiples of powers of x — a Taylor sum. Pseudo-code:
def apply_polynomial( deriv, x ):
sum = 0
for i from 0 to length( deriv ):
sum += deriv[i] * pow(x, i) / factorial(i)
return sum
It turned out that this function was a significant bottleneck in the execution time of my program: about 20% of it was spent inside this function. I was reasonably sure that the pow and factorial functions were the issue. I also knew that this function would only ever be called with cubics and lower-degree polynomials. So I re-wrote the code as follows:
def apply_cubic( deriv, x ):
sum = 0
len = length( deriv )
if len > 0:
sum += deriv[0]
if len > 1:
sum += deriv[1] * x
if len > 2:
square = x * x
sum += deriv[2] * square / 2
if len > 3:
cube = square * x
sum += deriv[3] * cube / 6
return sum
Sure enough, this improved the runtime significantly — by nearly the whole 20% that had been being spent inside this function. But notice that the code no longer contains the elements that define a Taylor sum: the loop is gone, and the factorials (0!, 1!, 2!, 3!) have been replaced with their values (1, 1, 2, 6). It also isn’t obvious why the length comparisons stop at 3. The code no longer explains itself, and must be commented to be understood. Readability has been sacrificed on the altar of efficiency.
Question
Why am I cursed so? Why can’t these metrics go hand-in-hand? And in general, why am I always doing this sort of thing? Sacrificing flavor for nutrition in the cafeteria, sacrificing walking-speed for politeness on a crowded sidewalk? Why are my goals so often set against one another?
Answer
Let’s take a second to think about what a trade-off is.
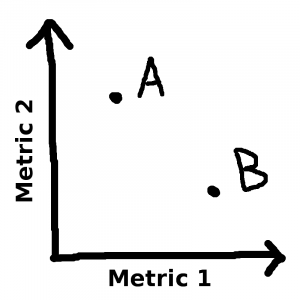
Suppose you’re faced with a problem to solve. You have two solutions in mind (Solution A & Solution B), and you have two metrics (Metric 1 & Metric 2) by which to judge a solution. A trade-off occurs when the solution that scores better along Metric 1 scores worse along Metric 2:
For example:
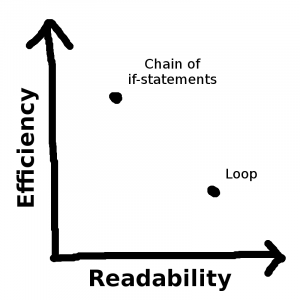
Of course, there need not be only two possible solutions. Maybe I’m willing to spend two hours working on improving this function, and depending on what I focus on, I could achieve any of the following balances:
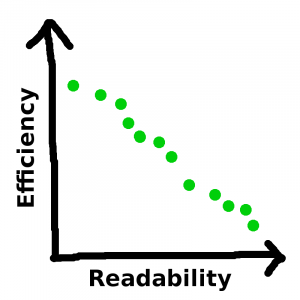
And — argh! The correlation is negative! Why!
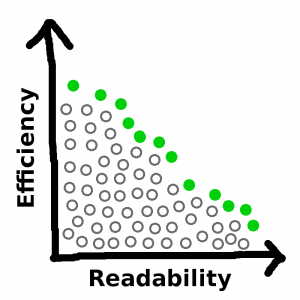
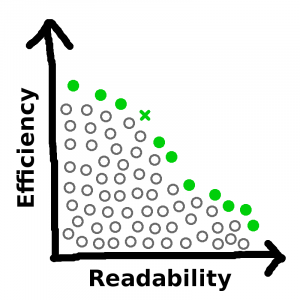
Well, there’s a reason, and the reason is that this isn’t the full picture. This is:
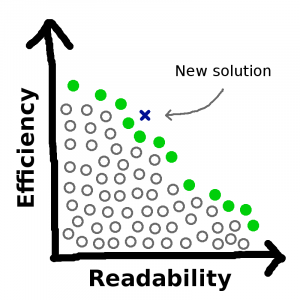
See, there are a whole bunch of ways to write the code that are neither as efficient nor as readable as one of the filled-in circles on the perimeter. But I would never choose any of those ways, for obvious reasons. And if a new solution occurs to me that beats out some of my old solutions along both metrics…
…then this new solution would replace all the solutions strictly worse than it, which in turn would become part of the mass that resides below the curve:
No matter how many new solutions are introduced into the mix, and no matter by how far they out-perform the old solutions, the outer frontier of non-dominated solutions must have negative slope everywhere. A step to the right along this line must be accompanied by a step downward, because if it isn’t, then the solution you just stepped off of is dominated by the one you just stepped onto, so the former wasn’t on the line.
It doesn’t take any math to generalize this result to situations where you have more than two metrics. Any solution that is dominated by another solution will be thrown out, so the options you end up considering form a set where no element dominates another, a.k.a. one where a gain along one metric entails a loss along at least one other, a.k.a. a trade-off. Throwing out obviously-poor solutions is easy (and is sometimes done subconsciously when you’re working in your domain of expertise, or done by other people before a decision gets to you), but weighing the remaining options usually takes some consideration. So, our subjective experience is that we spend most of our time and energy thinking about trade-offs. Q.E.D.
Note: On the LessWrong post, the user Dagon has written a comment explaining something that I meant to make more explicit in this post. Since they’ve expressed it better than I can, I’m just going to copy-paste their comment here:
One reason that most of your actual decisions involve tradeoffs is that easy no-tradeoff decisions get made quickly and don’t take up much of your time, so you don’t notice them. Many of the clear wins with no real downside are already baked into the context of the choices you’re making. For the vast majority of topics you’ll face, you’re late in the idea-evolution process, and the trivial wins are already in there.










{kind=link}
{kind=link}